BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
4.6 (574) · $ 18.50 · In stock


Mark Kurtz on X: New open-sourced research! BERT-Large (345M params) is now faster than DistilBERT (66M params) while maintaining accuracy. 8x to 11x faster using SOTA model compression techniques. Check it out

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

miro.medium.com/v2/resize:fit:1400/1*a-zIn_3V253rF
BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
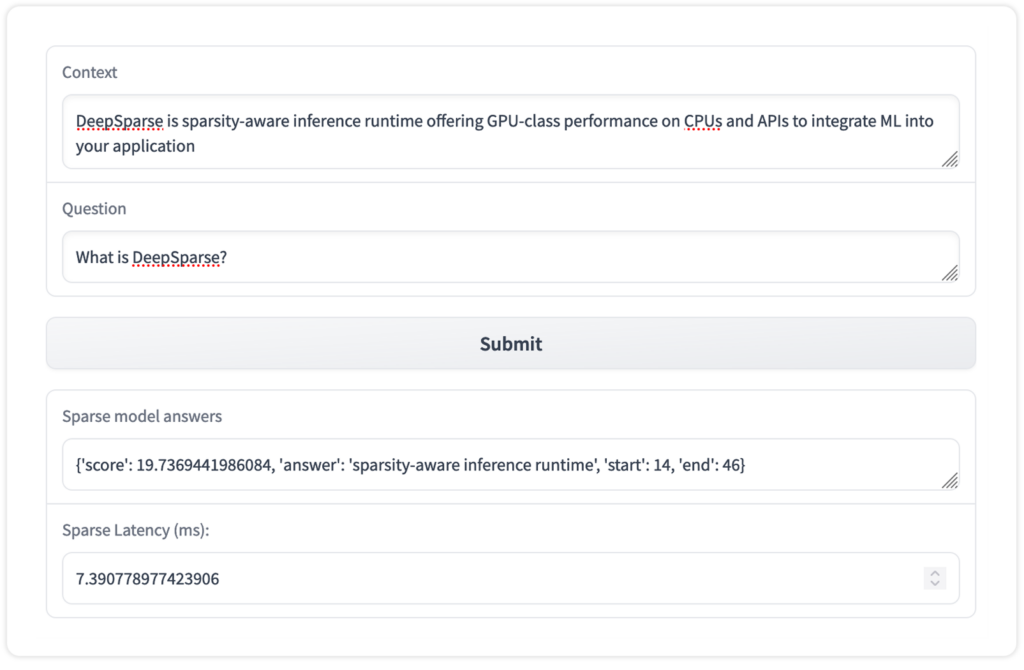
Deploy Optimized Hugging Face Models With DeepSparse and SparseZoo - Neural Magic

Running Fast Transformers on CPUs: Intel Approach Achieves Significant Speed Ups and SOTA Performance

Speeding up BERT model inference through Quantization with the Intel Neural Compressor

miro.medium.com/v2/resize:fill:1200:632/g:fp:0.54





