Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
4.7 (453) · $ 12.00 · In stock


Deploying deep learning networks based advanced techniques for image processing on FPGA platform
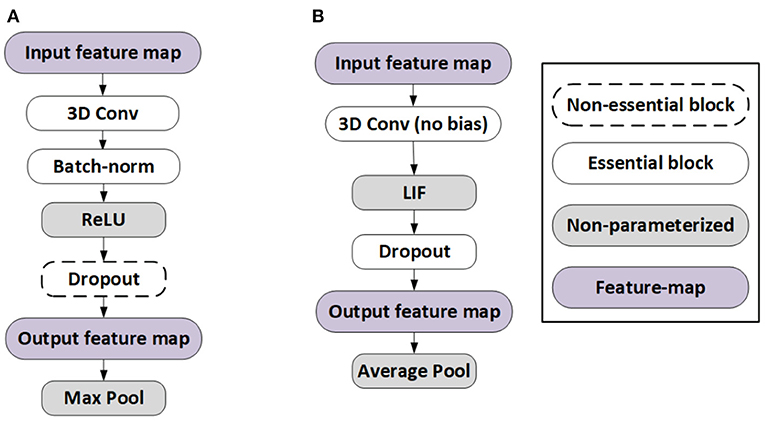
Frontiers ACE-SNN: Algorithm-Hardware Co-design of Energy-Efficient & Low- Latency Deep Spiking Neural Networks for 3D Image Recognition
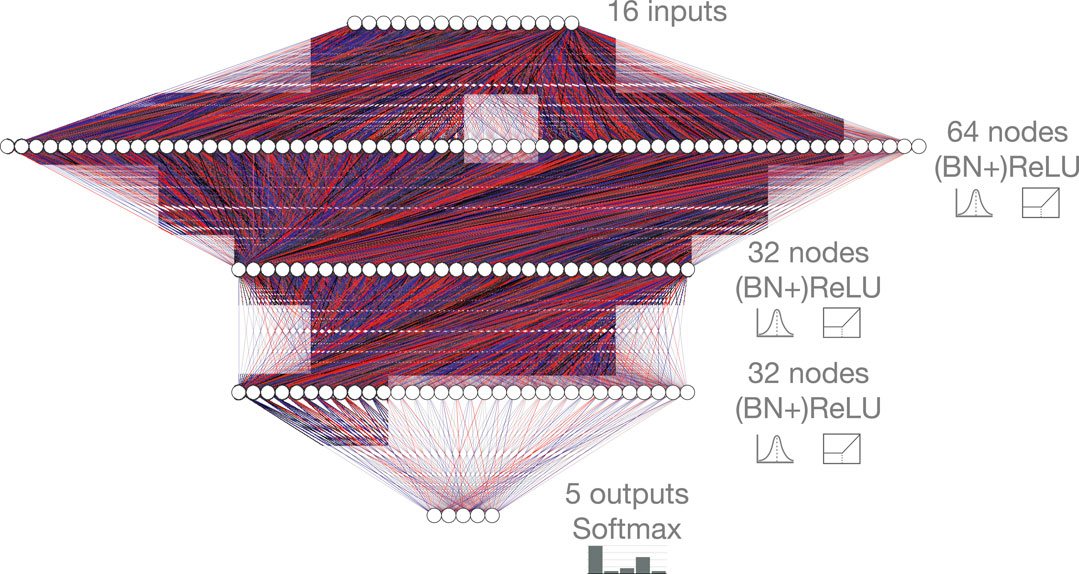
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

Frontiers Quantization Framework for Fast Spiking Neural Networks

Enabling Power-Efficient AI Through Quantization

A2Q+: Improving Accumulator-Aware Weight Quantization
![2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors](https://ar5iv.labs.arxiv.org/html/2006.10159/assets/x5.png)
2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors
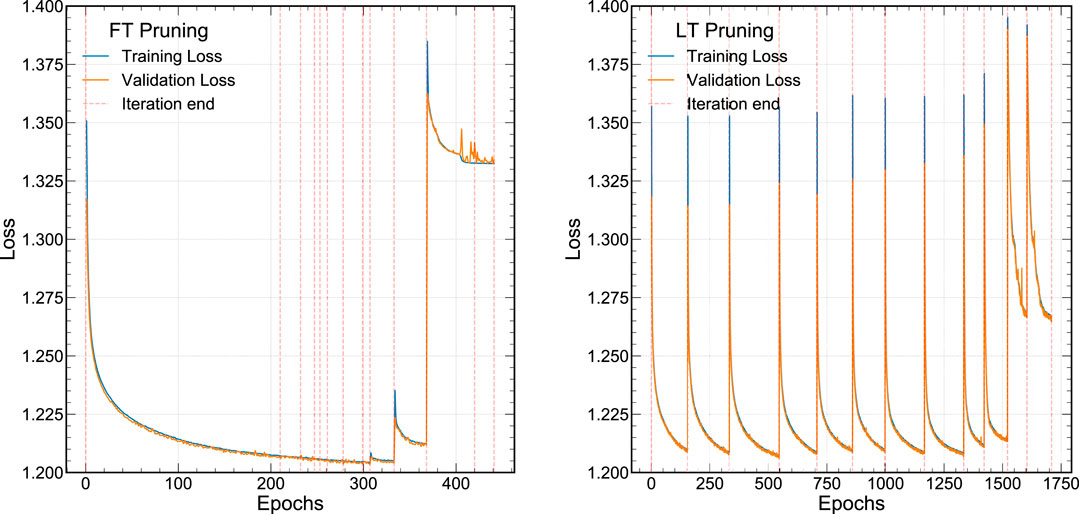
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

Loss of ResNet-18 quantized with different quantization steps. The

Enabling Power-Efficient AI Through Quantization
![2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors](https://ar5iv.labs.arxiv.org/html/2006.10159/assets/x6.png)
2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors

Frontiers in Artificial Intelligence Big Data and AI in High Energy Physics

Pruning and quantization for deep neural network acceleration: A survey - ScienceDirect

Quantization Framework for Fast Spiking Neural Networks. - Abstract - Europe PMC