The LLM Triad: Tune, Prompt, Reward - Gradient Flow
4.8 (563) · $ 17.50 · In stock

As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"

Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami

Fit Your LLM on a single GPU with Gradient Checkpointing, LoRA, and Quantization: a deep dive, by Jeremy Arancio

Understanding RLHF for LLMs

Maximizing Rewards with Policy Gradient Methods and Monte Carlo Reinforcement Learning- Part 2(Reinforcement Learning), by Ankush k Singal, AI Artistry
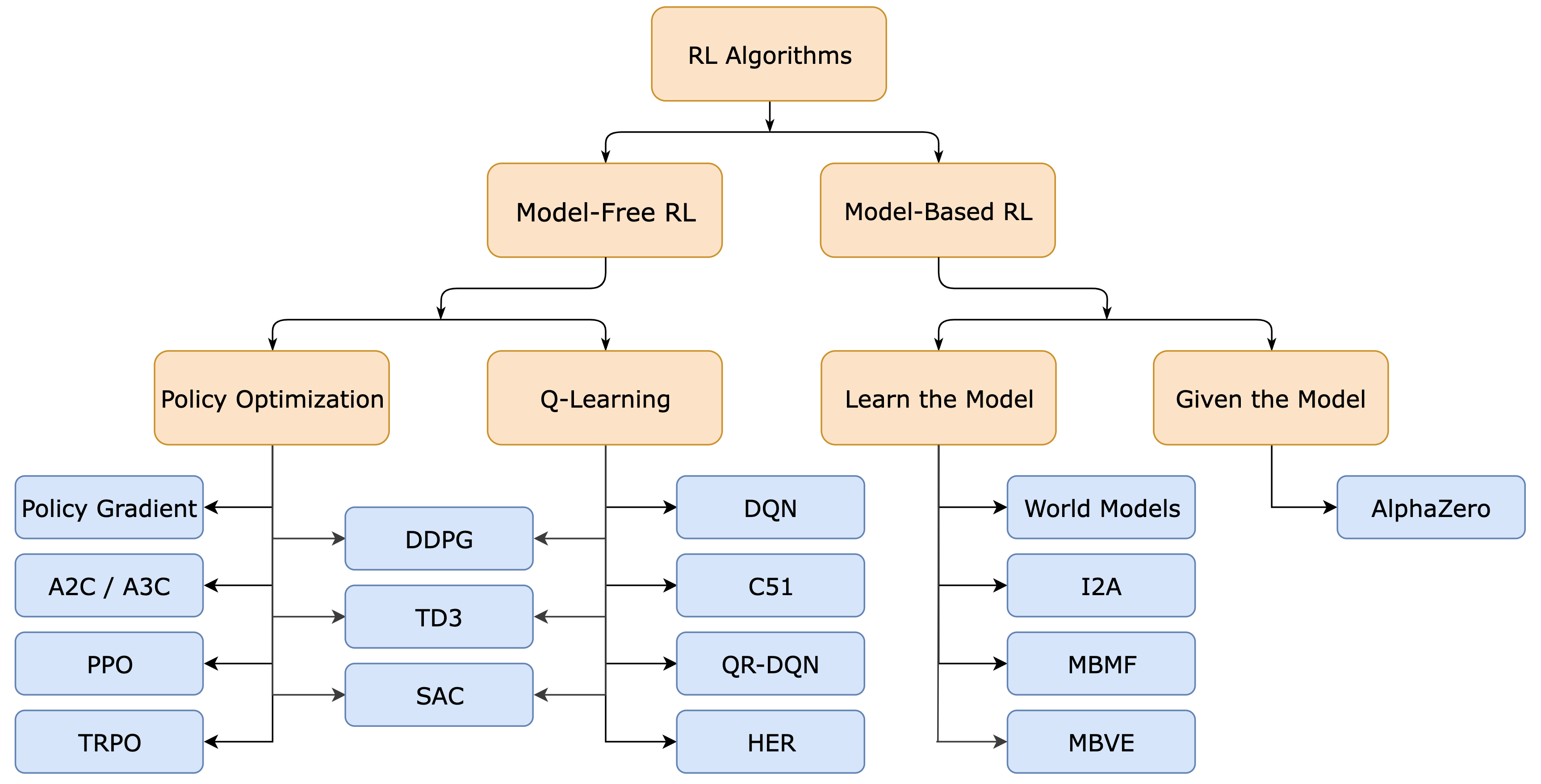
Understanding RLHF for LLMs

RLHF + Reward Model + PPO on LLMs, by Madhur Prashant
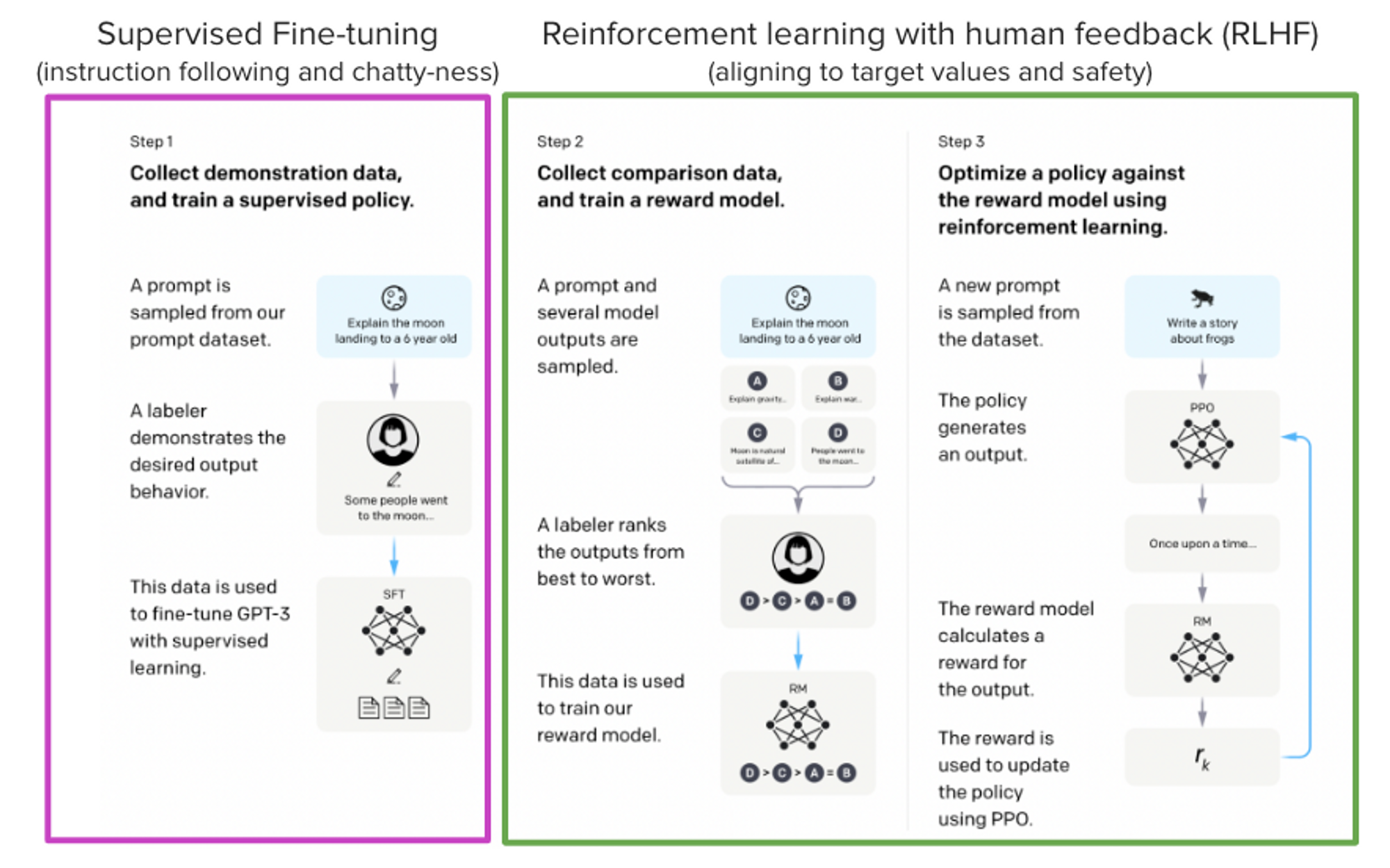
Understanding RLHF for LLMs
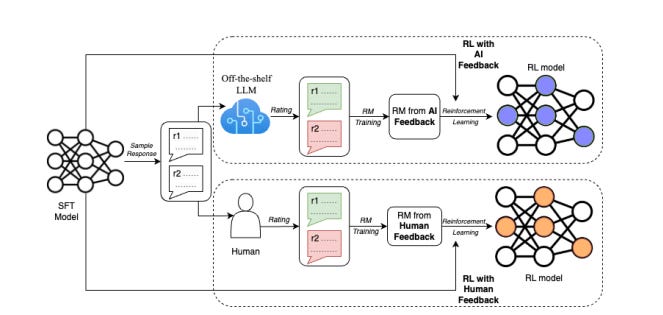
Fine-Tuning LLMs with Direct Preference Optimization

Building an LLM Stack Part 3: The art and magic of Fine-tuning
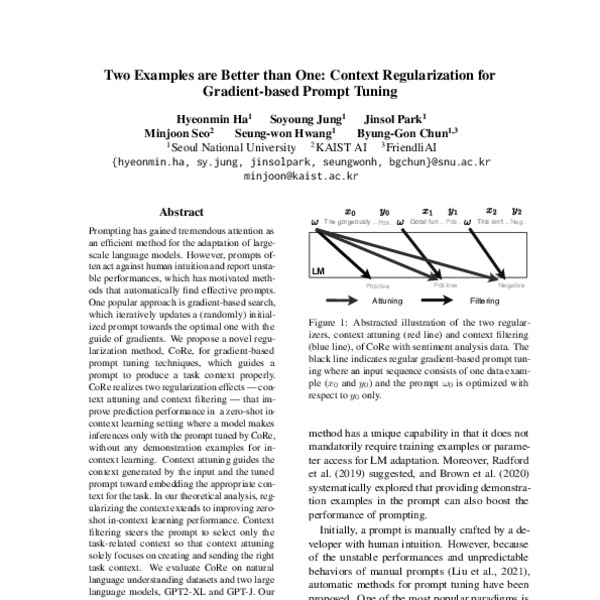
Two Examples are Better than One: Context Regularization for Gradient-based Prompt Tuning - ACL Anthology

,aspect=fit)





