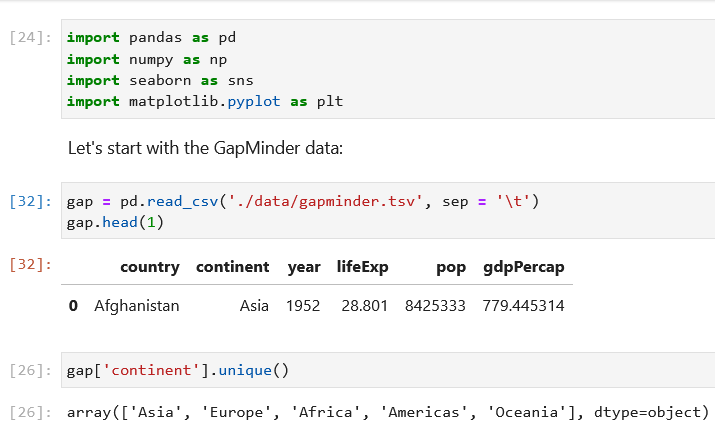
DistributedDataParallel non-floating point dtype parameter with
4.7 (421) · $ 11.50 · In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
How much GPU memory do I need for training neural nets using CUDA? - Quora

How to train on multiple GPUs the Informer model for time series forecasting? - Accelerate - Hugging Face Forums
expected scalar type Half but found Float with torch.cuda.amp and torch.nn.DataParallel · Issue #38487 · pytorch/pytorch · GitHub

Sharded Data Parallelism - SageMaker

Pipeline — NVIDIA DALI 1.36.0 documentation

PyTorch Numeric Suite Tutorial — PyTorch Tutorials 2.2.1+cu121 documentation
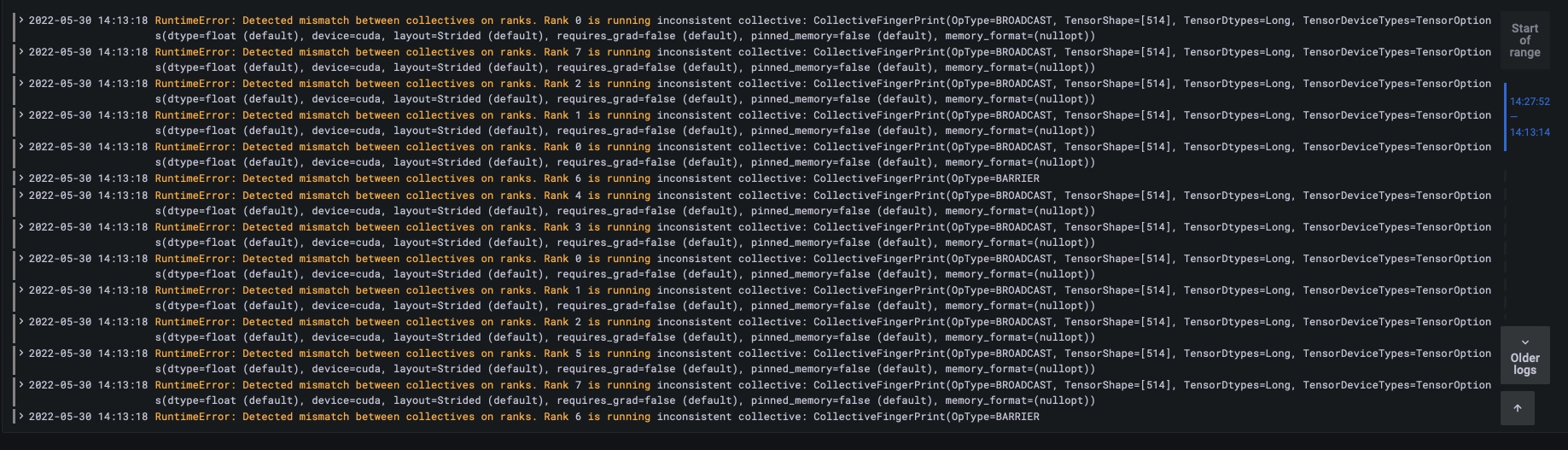
Detected mismatch between collectives on ranks - distributed - PyTorch Forums

Pytorch Lightning Manual Readthedocs Io English May2020, PDF, Computing

Distributed PyTorch Modelling, Model Optimization, and Deployment

DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
apex/apex/parallel/distributed.py at master · NVIDIA/apex · GitHub

Configure Blocks with Fixed-Point Output - MATLAB & Simulink - MathWorks Nordic
DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
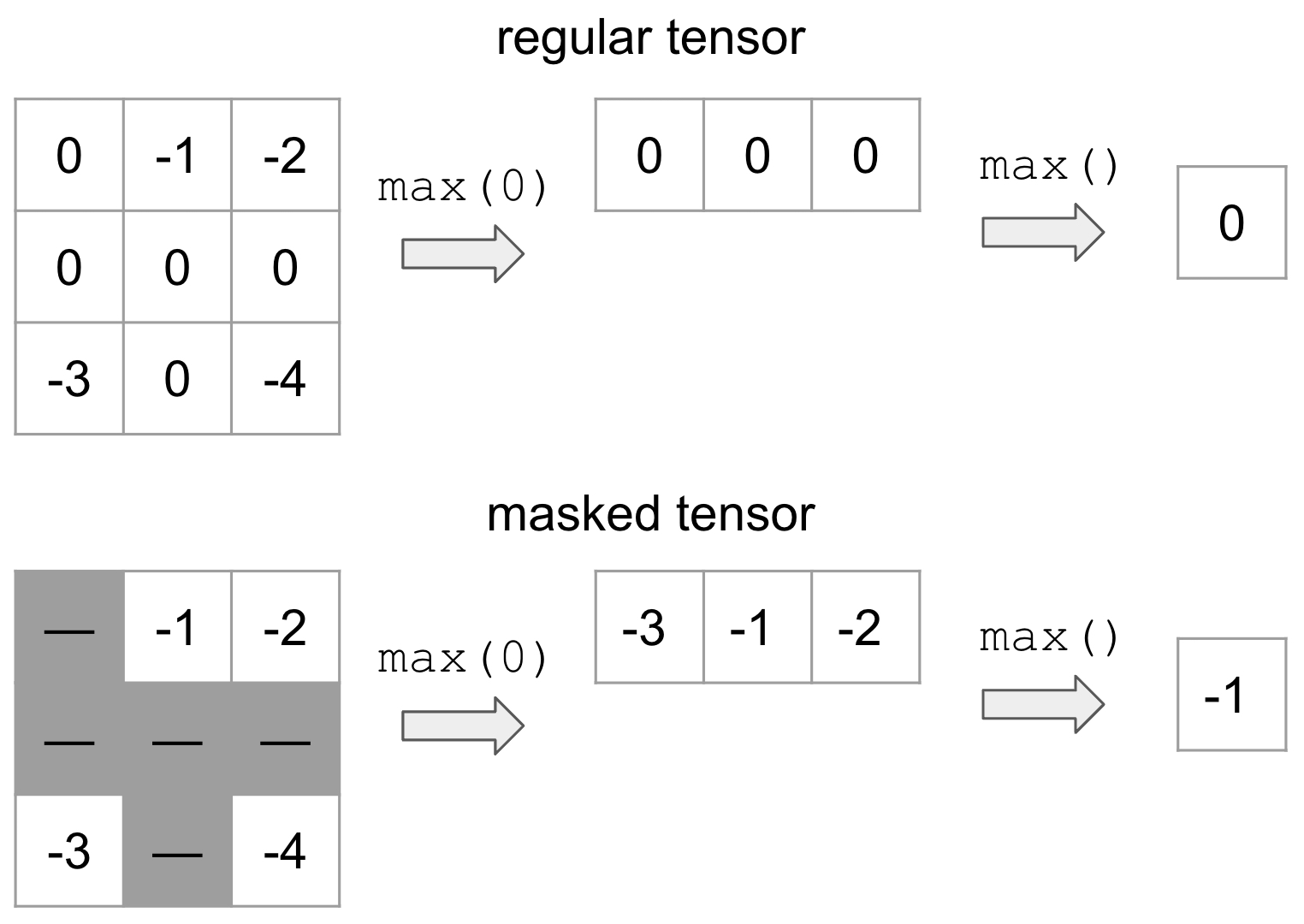
torch.masked — PyTorch 2.2 documentation