The Battle of the Compressors: Optimizing Spark Workloads with
4.5 (732) · $ 8.99 · In stock
Hello! Hope you’re having a wonderful time working with challenging issues around Data and Data Engineering. In this article let’s look at the different compression algorithms Apache Spark offers…
Easy Guide to Create a Custom Read Data Source in Apache Spark 3, by Amar Gajbhiye
Bucketing: Are you leveraging it in a right way ?, by Aditya Sahu, Curious Data Catalog

Improving Spark job performance while writing Parquet

Big Data with Spark and Scala. Big Data is a new term that is used…, by Jidnasa Pillai

Spark on K8s — Send Spark job's Metrics to DataDog Using Autodiscovery, by James (Anh-Tu) Nguyen, Geek Culture

A gentle introduction to Apache Arrow with Apache Spark and Pandas, by Antonio Cachuan

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre

The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet, by Siraj

Data processing with Spark: ACID, by Petrica Leuca

Advanced Spark Tuning, Optimization, and Performance Techniques, by Garrett R Peternel

Load Data using EMR Spark with Apache Iceberg, by Vishal Khondre
Spark it up a notch II. Nitty-gritty details on pyspark…, by Jyotsna Parthasarathy
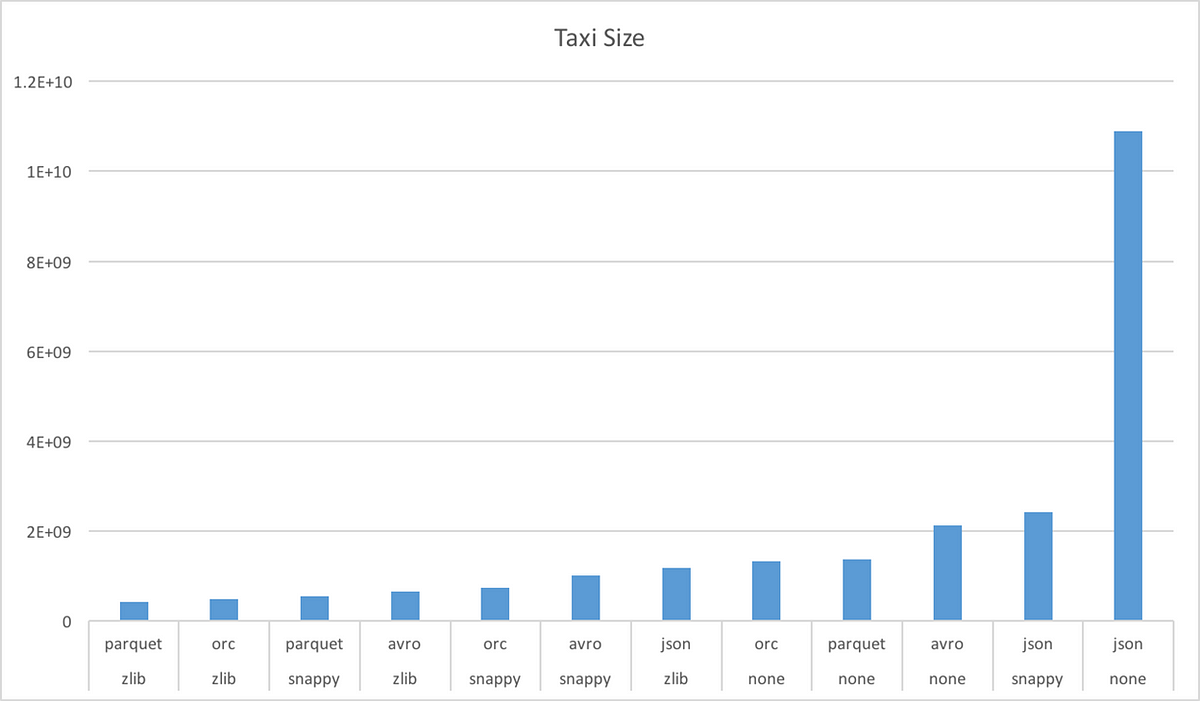
Avro vs Parquet. Let's talk about the difference between…, by Park Sehun
Optimizing Apache Spark File Compression with LZ4 or Snappy, by Matthew Salminen
Distributed Computing 101: An Introduction to the World of Parallel Processing, by Siraj